Find principle components, i.e. orthogonal directions that are computed via the SVD of a centered data matrix
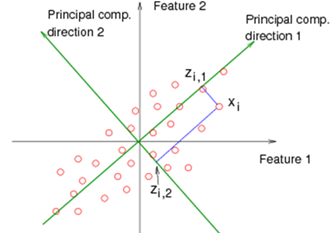
Think of a cloud of data and if we can project all of the points on only 2 lines, then we would want the line to be in the direction of the largest variances in order to capture the most information
Rank-one affine approximation:
Basic idea:
We can use SVD to to find the line passing through 0 that best approximates data points (i.e., the projection of the points on the line gives the lowest approximation error)
Let X:=[x1,...,xm] be a n×m data matrix, with each column xi∈Rn a data point
We seek to find a line L:={x0+αp:α∈R} with x0,p∈Rn to be determined, so that the projected points on the line are closest to the original ones.
If all the points are approximately on such a line then xi≈x0+qip for some qi∈R,i=1,...,m so that X≈x01⊺+pq⊺
where 1 is the m-vector of ones
This leads to the problem minx0,p,q∣∣X−x01⊺−pq⊺∣∣F2 where x0 and p,q∈Rm are both variables
and the optimal x0 is x^=m1∑i=1mxi
So the problem can be reduce to a standard rank-one problem minp,qc∣∣Xc−pqc⊺∣∣F2
where qc=q−q^1 and q^=m1∑i=1mqi and Xc is the centered data matrix Xc=[x1−xˉ,...,xm−xˉ]
PCA
Deflation:
Once we’ve found a line close to the cloud of points, can we repeat the process and find another one that is closest again
Deflation method:
Project data points on the hyperplane orthogonal to the direction we found
Find a new direction of for the projected data.
Iterate
Stop until when got k dimensions
Geomtric of deflation: project the data on a hyperplane orthogonal to the line with direction 1, then a line that is on the plane, orthogonal to the first direction, is found
Setup:
After SVD, we have centered data matrix n×m, Xc=X−x^1⊺=US~V⊺=∑i=1rσiuivi⊺ where:
S~ is a n×m diagonal matrix S~=diag(σ1,...,σr,0,...,0)
U:=[u1,...,un] and V:=[v1,..,vm] are orthogonal
we have x=z+z⊥ where z⊥z⊥; therefore, z⊥−x0=(I−uu⊺)(x−x0)
After projecting the points on the closest line, the (centered) matrix of projected points is Z(1)=u1u1⊺Xc while the points projected on the orthogonal to the line are Xc(1)=P1Xc where P1:=I−u1u1⊺
Since U is orthonormal, the projected points Xc(1) can be written as Xc(1)=P1∑i=1rσiuivi⊺=∑i=2rσiuivi⊺=US~(2)V⊺
where S~(2):=diag(0,σ2,....,σr,0,...,0)
In effect we have removed the component (dyad) associated with σ1
Note that the new data matrix is centered, and has largest singular value σ2, with the corresponding direction u2.
Together, u1,u2 span the closest plane approximating data
After k steps of the deflation process, the directions returned are u1,...,uk; spanning the closest k-dimensional subspace.
Thus we can compute all the principal components with one SVD of the original centered data matrix
Approximation error:
The sum of the squared lengths of the distances of points project to the line measures the error between points and their projections.
Explained variance:
At the first step, the average squared error between the (centered) original points and the points projected on the closest line is ∣∣Xc−Z(1)∣∣F2=∣∣P1Xc∣∣F2=σ22+...+σn2
After the k-th step, the error is thus ∣∣Xc−Z(k)∣∣F2=∣∣(Pk...P1)Xc∣∣F2=σk+12+...+σn2
The explained variance is the ratio 0≤ρ2:=σ12+...+σn2σk+12+...+σn2≤1
Data projection:
Once we computed the SVD of the centered data matrix, we can project the data on the plane spanned by the two vectors u1, u2.
This plane is the plane closest to data. The (centered) projected points are the 2D vectors in Z:Z=[z1,...,zm]=(u1⊺u2⊺)Xc
More generally, the span of {u1,...,uk} is the subspace of dimension k closest to the data set (this comes directly from the low-rank approximation theorem). The projected points are given by Z=[z1,...,zm]=u1⊺...uk⊺Xc
Link between SVD and eigenvalue decomposition of covariance:
Consider a centered matrix of data points Xc
The covariance matrix can be written as C=m1i=1∑m(xi−x^)(xi−x^)T=m1XcXcT,x^:=m1i=1∑mxi
If Xc has SVD Xc=US~VT, then C=U∧UT, where Λ:=m1diag(σ12,…,σr2,0,…,0)
Thus, the left singular vectors of Xc are the eigenvectors of C.
Variance Maximization problem:
Let C be the sample n×nCovariance Matrix for a data set of m points x1,...,xm∈Rn with mean x^=(1/m)(x1+...+xm)
For a given n-vector u, the line L(xˉ,u) of points of the form x^+αu
for α∈R
knowing that the projected data points are of the form zi=x^+αiui for αi=u⊺(xi−xˉ)
We seek a direction u such that the variance of the projected points on the line L(x^,u) is maximal. Without loss of generality, we can assume ∣∣u∣∣2=1
The variance of scores (m-vectors α) is m1∑i=1m[u⊺(xi−x^)]2=yTCu
We wish to maximize maxuuTCu:∣∣u∣∣2=1
Solution: an optimal vector u∗=u1 with u1 an eigenvector of C that corresponds to its largest eigenvalue λ1
Projection on maximum variance line:
The line with maximum variance is set of points of the form x^+αu1
The projection of a generic point x∈Rn on the line is z=x^+(u1⊺(x−x^))u1=x^+u1u1T(x−x^)
We can project all the data points at once: the (centered) matrix of projected points is the dyad: Z(1)=[z1(1)−x^,...,zm(1)−x^]=u1u1TXc
The line of maximum variance minimizes the sum of squared Euclidean norm distance between the data points and the line.
In fact, PCA can be interpreted two ways:
as a variance maximization process, relying on the eigenvalue decomposition of the covariance matrix;
as a low-rank approximation of the centered data matrix, relying on the SVD of that matrix
Minimum distance line:
The projection z of x along line x^+αu is z=x^+uuT(x−x^)
So the sum of squared distances between x(i) and its projection z(i) is
Hence, minimizing the sum of squared distances is the same as maximizing (1/m)∑i(uTxc(i))2, that is, the variance of the projected points.
Rank-one approximation:
Consider the centered data matrix Xc=[xc(1)⋯xc(m)] and assume we want to find the rank-one matrix matrix σuvT that best approximates Xc in the Frobenius norm sense: minσ,u,vXc−σuvTF2,σ≥0,∥u∥2=∥v∥2=1